
Improving code review time at Meta
- Code testimonials are one of the most essential elements of the computer software development course of action
- At Meta we’ve acknowledged the will need to make code opinions as fast as feasible with no sacrificing top quality
- We’re sharing several resources and steps we have taken at Meta to lower the time ready for code reviews
When completed nicely, code opinions can capture bugs, train ideal tactics, and be certain large code excellent. At Meta we connect with an individual set of modifications manufactured to the codebase a “diff.” Though we like to go fast at Meta, each and every diff have to be reviewed, with no exception. But, as the Code Evaluate workforce, we also understand that when opinions choose for a longer time, people get fewer carried out.
We have researched several metrics to study additional about code critique bottlenecks that direct to sad developers and applied that information to establish functions that support velocity up the code review course of action with out sacrificing evaluate high-quality. We’ve observed a correlation in between sluggish diff overview occasions (P75) and engineer dissatisfaction. Our resources to floor diffs to the right reviewers at important times in the code evaluation lifecycle have drastically enhanced the diff evaluation expertise.
What would make a diff overview feel gradual?
To response this query we started off by on the lookout at our information. We track a metric that we get in touch with “Time In Evaluate,” which is a measure of how extended a diff is waiting around on overview throughout all of its unique overview cycles. We only account for the time when the diff is waiting on reviewer action.
What we uncovered stunned us. When we appeared at the data in early 2021, our median (P50) hours in overview for a diff was only a couple several hours, which we felt was very fantastic. Even so, searching at P75 (i.e., the slowest 25 {64d42ef84185fe650eef13e078a399812999bbd8b8ee84343ab535e62a252847} of reviews) we observed diff review time boost by as substantially as a working day.
We analyzed the correlation concerning Time In Critique and person fulfillment (as measured by a enterprise-wide survey). The effects were clear: The extended someone’s slowest 25 per cent of diffs choose to assessment, the a lot less glad they were by their code evaluation system. We now experienced our north star metric: P75 Time In Assessment.
Driving down Time In Assessment would not only make persons more glad with their code overview procedure, it would also enhance the efficiency of each engineer at Meta. Driving down Time to Evaluate for our diffs usually means our engineers are expending considerably a lot less time on reviews – generating them additional productive and far more pleased with the overall overview process.
Balancing velocity with high-quality
However, simply optimizing for the pace of assessment could guide to damaging facet effects, like encouraging rubber-stamp examining. We necessary a guardrail metric to protect in opposition to damaging unintended consequences. We settled on “Eyeball Time” – the total amount of time reviewers spent on the lookout at a diff. An improve in rubber-stamping would lead to a reduce in Eyeball Time.
Now we have set up our target metric, Time In Assessment, and our guardrail metric, Eyeball Time. What arrives up coming?
Make, experiment, and iterate
Practically just about every merchandise crew at Meta makes use of experimental and data-pushed procedures to launch and iterate on attributes. Nevertheless, this course of action is nonetheless really new to inside equipment groups like ours. There are a quantity of troubles (sample sizing, randomization, network result) that we have had to get over that merchandise groups do not have. We address these problems with new knowledge foundations for operating network experiments and utilizing tactics to reduce variance and improve sample sizing. This additional effort is truly worth it — by laying the foundation of an experiment, we can later on demonstrate the impression and the success of the capabilities we’re setting up.

Upcoming reviewable diff
The inspiration for this characteristic arrived from an unlikely place — video streaming solutions. It’s uncomplicated to binge view demonstrates on specific streaming products and services for the reason that of how seamless the transition is from a person episode to an additional. What if we could do that for code critiques? By queueing up diffs we could persuade a diff critique move state, permitting reviewers to make the most of their time and mental electrical power.
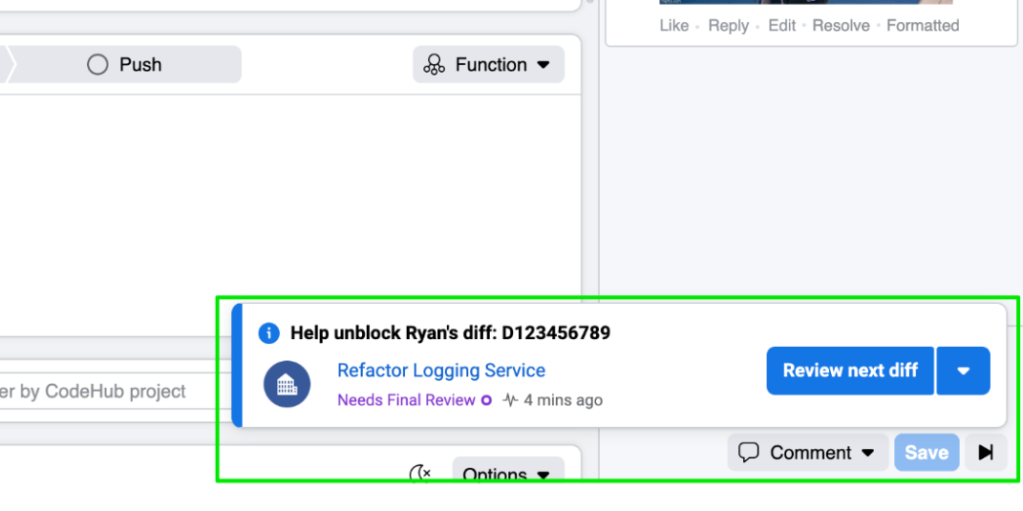
And so Up coming Reviewable Diff was born. We use equipment mastering to determine a diff that the recent reviewer is hugely most likely to want to critique. Then we floor that diff to the reviewer immediately after they finish their present code evaluation. We make it simple to cycle as a result of doable upcoming diffs and swiftly get rid of by themselves as a reviewer if a diff is not pertinent to them.
After its start, we found that this attribute resulted in a 17 {64d42ef84185fe650eef13e078a399812999bbd8b8ee84343ab535e62a252847} overall enhance in critique actions per working day (these kinds of as accepting a diff, commenting, and many others.) and that engineers that use this movement conduct 44 percent far more overview steps than the common reviewer!
Bettering reviewer recommendations
The decision of reviewers that an author selects for a diff is quite important. Diff authors want reviewers who are going to overview their code nicely, promptly, and who are professionals for the code their diff touches. Traditionally, Meta’s reviewer recommender appeared at a limited established of knowledge to make tips, main to issues with new documents and staleness as engineers transformed groups.
We developed a new reviewer recommendation process, incorporating function hours consciousness and file possession facts. This will allow reviewers that are out there to review a diff and are more probably to be great reviewers to be prioritized. We rewrote the product that powers these tips to aid backtesting and automatic retraining far too.

The result? A 1.5 per cent boost in diffs reviewed inside 24 hrs and an increase in major 3 advice accuracy (how frequently the actual reviewer is just one of the top rated three proposed) from down below 60 {64d42ef84185fe650eef13e078a399812999bbd8b8ee84343ab535e62a252847} to virtually 75 percent. As an additional bonus, the new product was also 14 instances more quickly (P90 latency)!
Stale Diff Nudgebot
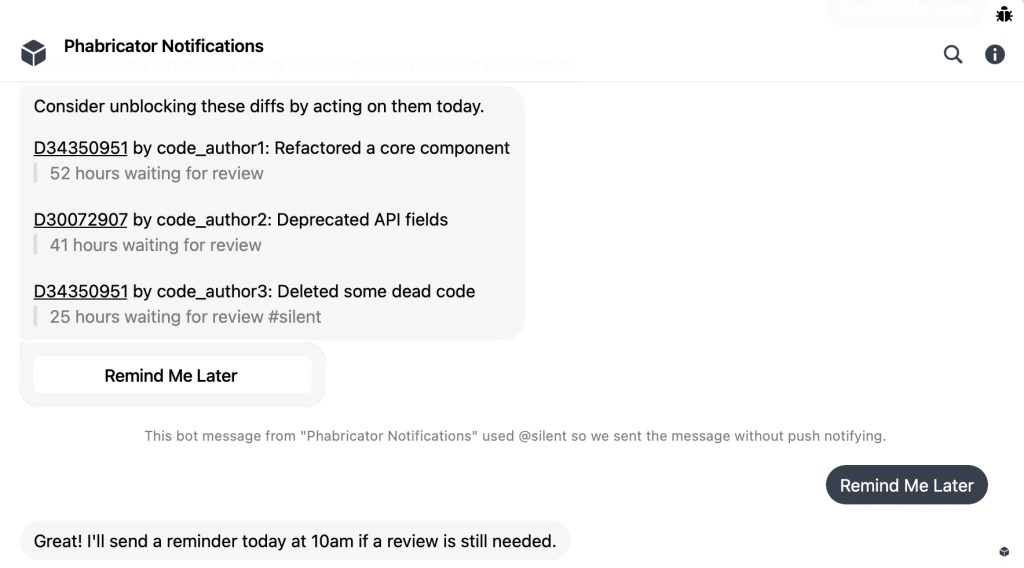
We know that a small proportion of stale diffs can make engineers unsatisfied, even if their diffs are reviewed immediately in any other case. Gradual testimonials have other effects also — the code itself turns into stale, authors have to context switch, and over-all productivity drops. To instantly tackle this, we designed Nudgebot, which was inspired by study finished at Microsoft.
For diffs that had been having an additional long time to overview, Nudgebot determines the subset of reviewers that are most most likely to assessment the diff. Then it sends them a chat ping with the appropriate context for the diff alongside with a set of rapid actions that permit recipients to leap suitable into examining.
Our experiment with Nudgebot experienced excellent benefits. The average Time In Review for all diffs dropped 7 percent (modified to exclude weekends) and the proportion of diffs that waited for a longer period than a few days for evaluation dropped 12 per cent! The results of this element was individually printed as well.
What will come subsequent?
Our present and long run operate is targeted on issues like:
- What is the right established of men and women to be examining a offered diff?
- How can we make it less difficult for reviewers to have the info they need to give a high top quality assessment?
- How can we leverage AI and machine discovering to boost the code critique method?
We’re continuously pursuing solutions to these inquiries, and we’re wanting forward to getting far more approaches to streamline developer processes in the potential!
Are you interested in setting up the long run of developer efficiency? Join us!
Acknowledgements
We’d like to thank the following people today for their enable and contributions to this write-up: Louise Huang, Seth Rogers, and James Saindon.







