The evolving role of the data engineer
It’s generally tempting to say that factors ended up basic in the previous times. But speak with any surviving COBOL or Fortran programmer, particularly those who experienced to deal with punch cards or rotating drums, and the aged days search something but uncomplicated. Nonetheless, when it arrived to engineering roles, there was a quite rudimentary breakdown: The systems man or woman dealt with the hardware and the application engineer presided around code.
The earth certainly has grow to be more challenging given that then. Emergence of dispersed units gave increase to databases that taken care of the knowledge exterior of the method, now known as an software. Computing languages proliferated like rabbits as simplified languages, this kind of as Visible Essential, gave hope of a dwelling wage for innumerable liberal arts majors.
That amplified the part of program engineering, as there necessary to be grownups in the home to guarantee that the code has been properly produced and maintained. New iterative, then agile software development processes supplanted traditional waterfall techniques. And as program architectures grew extra dispersed and advanced, and computer software releases grew far more repeated with agile and scrums, software engineering had to element in functions – and so begat DevOps. Software package engineering was usually about complexity, but with dispersed systems and agile procedures, the character of the complexity modified.
But through all this, knowledge was regarded as an software challenge. Of course, you necessary database administrators to design and bodily lay out the facts, and then hold the databases buzzing. But the interactions with knowledge tended to slide into a couple of buckets: Transaction databases were mostly occupied by one row functions, though knowledge warehouses were mainly batch operation affairs.
Our individual journey through the area mirrored the perception. All through the client/server era and the run-up to Y2K, relational databases grew to become the default. When the net broke relational databases with their transaction volumes, the action shifted to the software server in the center tier, which dealt with condition management. And so, we spent the subsequent 10 years monitoring middleware.
But then the knowledge bought so humongous that it swung the pendulum the other way the air was sucked out of the middle tier as processing moved back again to the information. Major information. Polyglot knowledge. And so, operations versus data grew to become nearly anything but a shut-book affair. To layout nearly anything from ingest to intricate exploratory querying, builders producing MapReduce systems experienced to know not only Java, but the behavior of data, and a lot more specially, what was the ideal sequence of processing functions, not only to get the task completed, but get dependable results. And this was just before the cloud came in, which exploded scale even even further and pressured still a new pendulum swing for separating compute from storage.
Sorry to say, but this was no more time a software program engineering issue. An engineer was essential who knew the behavior and shape of the information. Enter, from phase left, the information engineer.
According to Certainly.com, facts engineering, along with total stack developer and cloud engineer, have supplanted information scientist as the most sought-following tech occupation. In all this maelstrom are a couple of self-described “recovering information experts,” Joe Reis and Matthew Housley, who leaped into the void of defining just what specifically a information engineer is.
We lately experienced the prospect to have a deep-dive discussion with them, far better known as the authors of the bestseller “Fundamentals of Info Engineering.” Both of those came to details engineering following data science stints, wherever they figured out the really hard way that they experienced to invest far more time wrestling with info in order to acquire, prepare and operate types. Their encounter extremely substantially jibed with research we executed all through our Ovum times just about five a long time back in conjunction with Dataiku. Particularly, that if you’re a info scientist, think about by yourself blessed if you only have to shell out 50 percent your time dealing with info.
So, what accurately is a knowledge engineer?
As famous above, information engineering emerged when the cloud and massive details manufactured data interaction far a lot more elaborate, scaled and dynamic when compared with the very good outdated days of jogging against a walled-yard database in the information middle. It emerged together with other disciplines these as web site dependability engineering that grew important due to the fact the cloud introduced additional shifting elements.
As at first envisioned, info engineering was an try to utilize the disciplines of program engineering to the data lifecycle. Reis and Housley get a lot more certain: It is about developing in screening, ongoing advancement and variation management to the information lifecycle and, stretching the envelope a bit, observability. With the cloud and large information, touching the information could no extended be addressed as a static, one-row insert or batch-course of action black box. Major information launched far more varied information varieties and sources, and the cloud released considerably more transferring areas.
Precisely, the cloud broke down all the regular boundaries that constrained info interactions in the knowledge center. All elements of infrastructure, from compute to storage and connectivity, grew significantly cheaper, taking edge of commodity engineering. It paved the way to decoupling all concentrations of the architecture, which meant a lot more parameters to offer with, and the need to have to improve.
Optimization is not a new strategy in the database world, but in the cloud, there is significantly a lot more floor spot to improve. Exclusively, the cloud improved from controlling potential to controlling source. The rationale for optimization, these types of as tiering information or pinpointing the suitable sequence of operations for a sophisticated question, has not changed. But there is the require to apply such imagining to extra “parts,” these types of as exactly where to change facts.
Need to it nonetheless be finished usually, outdoors the database (ETL), or in-database (ELT) since the storage is substantially less expensive? For occasion, even though ELT has develop into the extra common option, if streaming is concerned, traditional ETL (but executed on a stream-of-transform feed) may perhaps even now be the a lot more simple respond to.
In accordance to Reis and Housley, the profession or discipline of data engineering is nevertheless badly described, which is why they wrote their reserve. They have tried to dive into the void by defining specifications for abilities and knowledge. Evidently, there is a lot to borrow from computer software engineering, these kinds of as most effective practices for continual testing and integration in the context of functions. And from that will come the self-control of DataOps.
Reis and Housley emphasize that it involves additional than trusting your destiny to equipment and being a resources jockey: Appear under the hood to fully grasp how the resource does its job, or what’s lurking beneath the floor of an API. Comprehend what the instrument is accomplishing as if you had to code or configure the approach you.
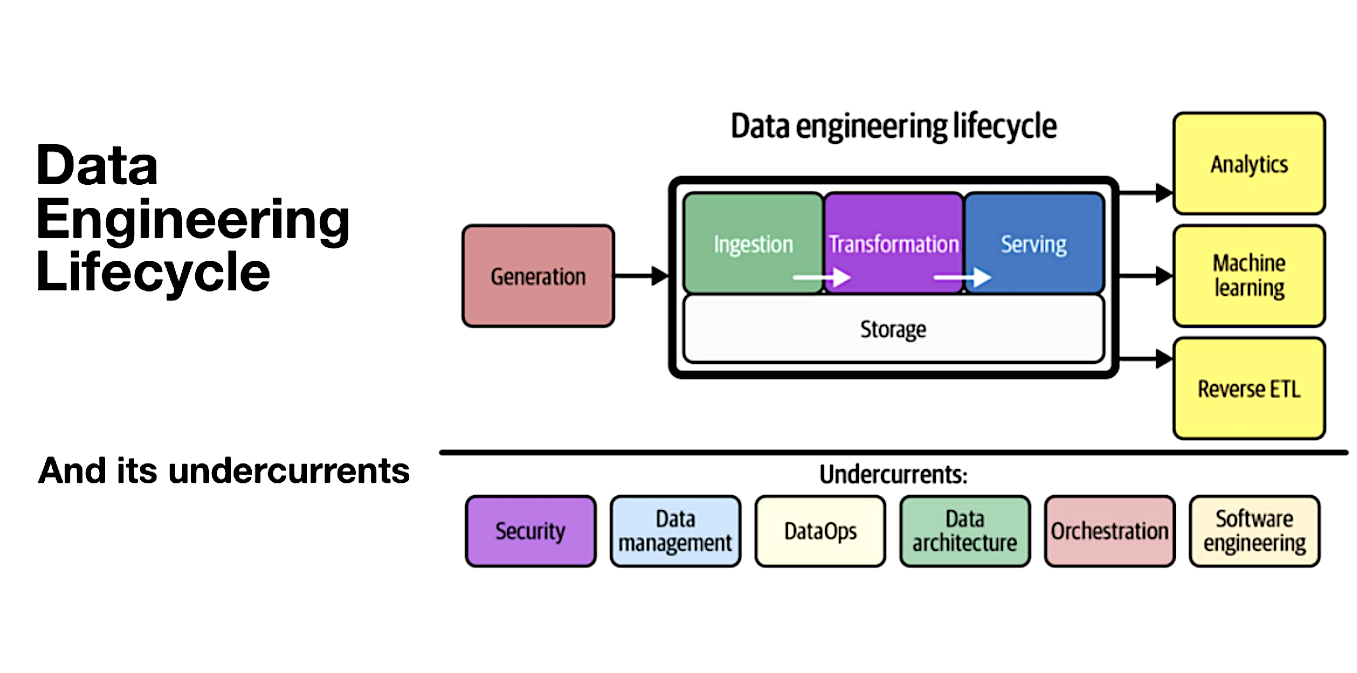
The Information Engineering Lifecycle (Resource: Ternary Knowledge)
The authors define the software package engineer’s work as owning the lifecycle from knowledge ingestion via transformation and serving (which is the delivery of information in its concluded type). There are numerous choice points at every single move of the way, these as no matter whether there is the need to consider advantage of an orchestration framework these types of as Apache Airflow to choreograph the methods in the info pipeline determining when, in which and how to transform details and then delivering the data in packaged form to company people.
Reis and Housley also contact upon facts engineers not simply just to be engineers, but to take into consideration them selves in the info company. Specifically, which is all about performing like an entrepreneur: realizing the customers, figuring out their specifications and knowing the main company of the organization. This goes significantly outside of stressing about feeds and speeds and the toolchain. This will need to know your consumer truly is a great in shape for organizations getting knowledge mesh strategies, the place knowledge is handled as a products that is managed throughout its lifecycle. The duties of info engineers in producing and sustaining pipelines and how data is sent to the customer are a subset of what contains a details product or service.
The globe has developed a good deal far more complex because the on-premises times in which interactions with databases were being well-defined transactions. To paraphrase Tom Davenport and DJ Patil, however facts engineering could no longer be the sexiest career of the 21st century, the authors up to date their pronouncement that data science and AI are seriously a workforce exertion, where information engineers between other people perform a pivotal position.
Tony Baer is principal at dbInsight LLC, which delivers an unbiased perspective on the database and analytics technology ecosystem. Baer is an business professional in extending knowledge administration techniques, governance and sophisticated analytics to handle the desire of enterprises to crank out meaningful worth from info-driven transformation. He wrote this posting for SiliconANGLE.